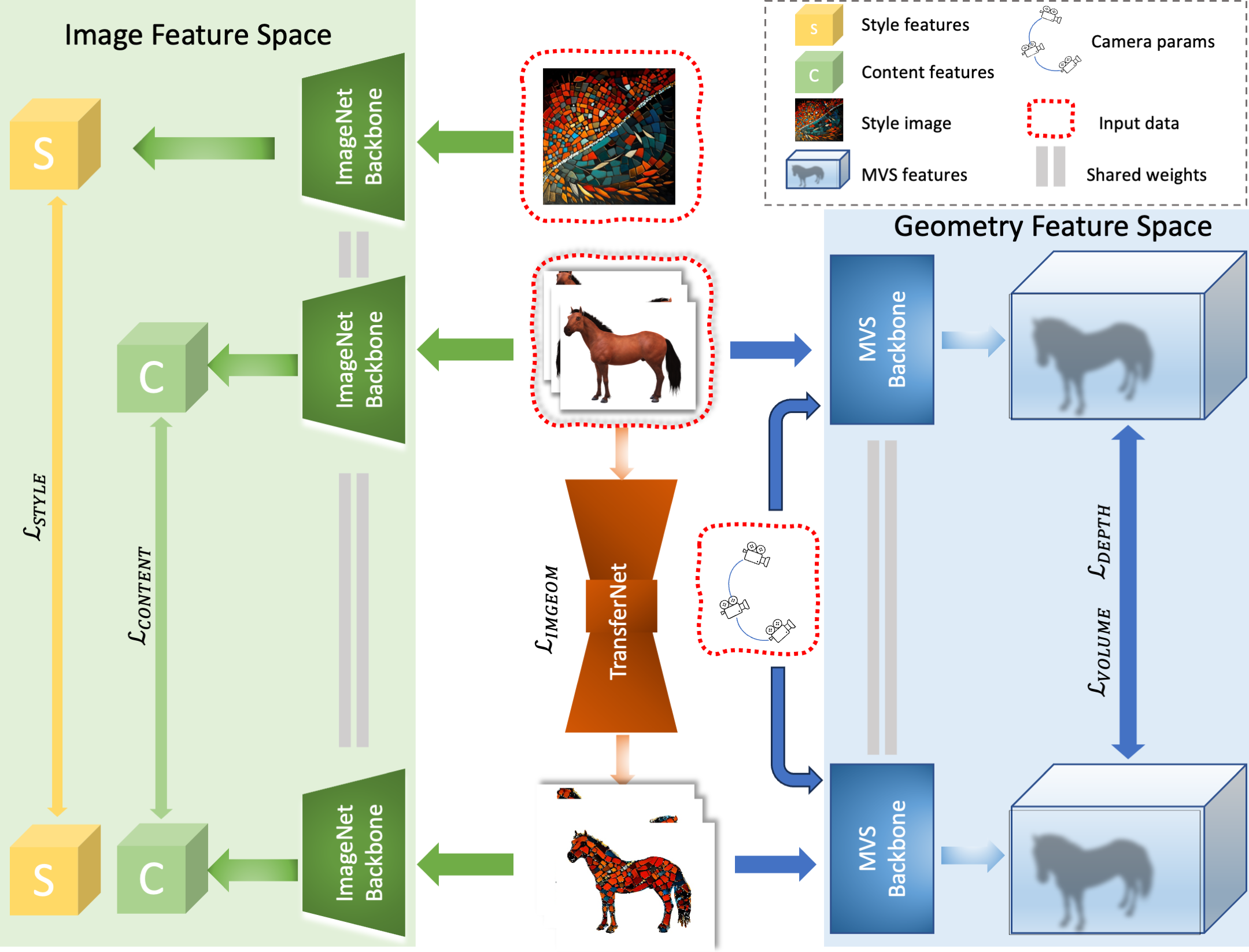
We present a modular multi-view consistent style transfer network architecture MuVieCAST that enables consistent style transfer between multiple viewpoints of the
same scene.
This network architecture supports both sparse and dense views, making it versatile enough to handle a
wide range of multi-view image datasets.
The approach consists of three modules that perform specific tasks related to style transfer, namely
content preservation, image transformation, and multi-view consistency enforcement.
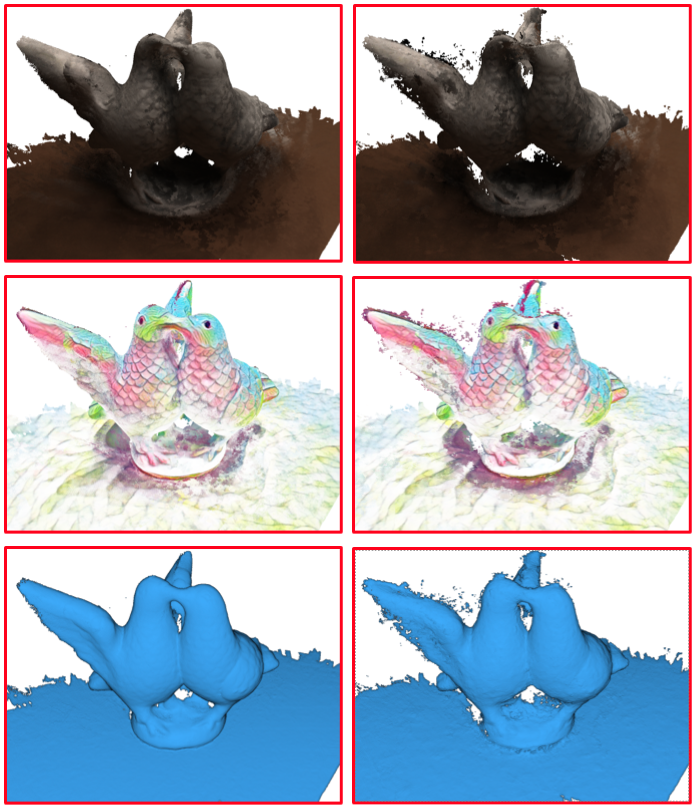
We evaluate our approach extensively across multiple application domains including depth-map-based point
cloud fusion, mesh reconstruction, and novel-view synthesis.
The results demonstrate that the framework produces high-quality stylized images while maintaining
consistency across multiple views, even for complex styles that involve mosaic tessellations or extensive
brush strokes.
Our modular multi-view consistent style transfer framework is extensible and can easily be integrated with
various backbone architectures, making it a flexible solution for multi-view style transfer.